Cross-Validation has two main steps: splitting the data into subsets (called folds) and rotating the training and validation among them. The splitting technique commonly has the following properties:
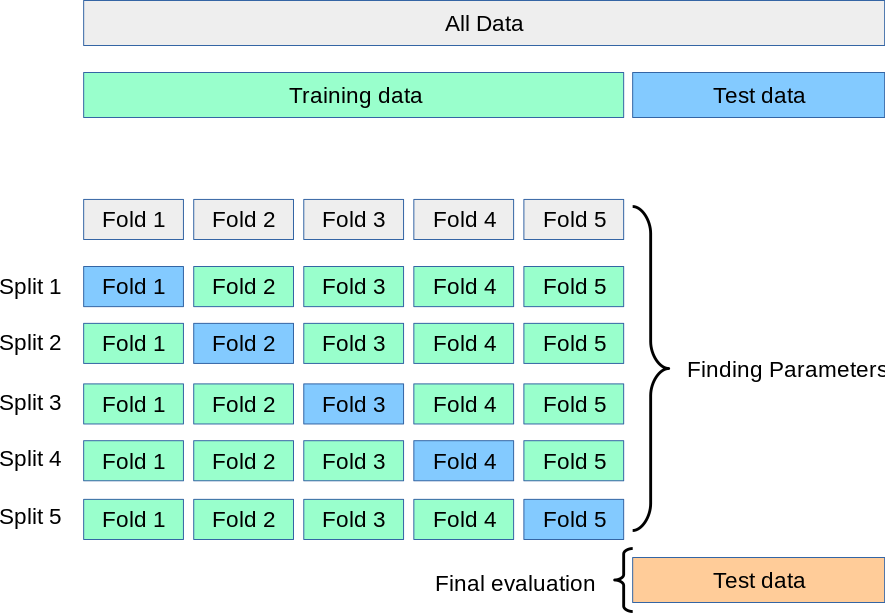
K-fold and CV are two terms that are used interchangeably. K-fold is just describing how many folds you want to split your dataset into. Many libraries use k=10 as a default value representing 90% going to training and 10% going to the validation set. The next figure describes the process of iterating over the picked ten folds of the dataset.
Figure 2 shows how one fold in each step iteratively is held out for testing while the remaining folds are used to build the model. Each step calculates the prediction error. Upon the completion of the final step, a list of computed error are produced of which we can take the mean.
Figure 3 shows the change in the training and validation sets’ size when using different values for k. The training set size increases whenever we increase the number of folds while the validation set decreases. Typically, the smaller the validation set, the likelihood that the randomness rises with a high noise variation. Increasing the training set size will increase such randomness and bring more reliable performance metrics.
One of the advantages of CV is observing the model predictions against all the instances in the dataset. It ensures that the model has been tested on the full data without testing them simultaneously. Variations are expected in each step of the validation; therefore, computing the mean and standard deviation can reduce the information into a few comparing values.
Cross validation is an important concept in statistics that refers to a model validation technique for assessing how the results of a statistical analysis will generalize to an independent data set. In other words cross validation allows you to test how well your model will perform on new data. This is crucial for evaluating and fine tuning your model to ensure accuracy and avoid common problems like overfitting. In this article, I’ll explain cross validation in simple terms why it’s useful, and some key techniques.
What Does Cross Validation Mean?
At its core, cross validation means splitting your data into two subsets – a training set and a validation set (also called a testing set). You fit or train your model on the training set, then test it on the validation set. This gives you a sense of how well your model will work on new unseen data, since the validation set was not used during training.
For example say you’re developing a machine learning model to predict housing prices. You have historical data on house features like size, location, etc. and the actual selling prices. You would train your model on a subset of the data, then test its predictions on the remaining “new” data to see how accurate it is.
Cross validation is used when your goal is prediction, to estimate the predictive accuracy of a model. It helps avoid problems like:
-
Overfitting – when a model fits the training data almost perfectly, but fails on new data. This happens when a model is too finely tuned to the training data.
-
Selection bias – when the training set is not representative of the real-world data.
By testing on a validation set, cross validation gives you an idea of how your model will generalize to independent data sets that reflect the real world.
Why Use Cross Validation?
There are a few key reasons cross validation is recommended:
-
Estimates predictive performance – By testing your model on data it hasn’t seen before, cross validation gives a better estimate of how well it will perform when deployed on new data. Training performance can be optimistically biased.
-
Avoids overfitting – Testing on an unseen validation set will reveal if your model has overfit on the training data. The larger the gap in performance between the training and validation sets, the more overfitting has likely occurred.
-
Model selection – Cross validation can help select the best model when you have multiple options by comparing their validation set performance. For example, which machine learning algorithm results in the lowest error on the validation data?
-
Hyperparameter tuning – Cross validation can be used to tune hyperparameters like selecting the optimal k in kNN models. Test different values to see which perform best on the validation sets.
Overall cross validation leads to models that are more robust, predictive, and less prone to overfitting by revealing a truer estimate of real-world performance. It’s a simple and accessible technique for better modeling.
Cross Validation Techniques
There are several common cross validation techniques, each with their own pros and cons:
-
Holdout Method – Split data into two sets, a training and test set. Simple but results can depend heavily on the specific split.
-
K-Fold – Split data into k equal folds. Use each fold as a validation set and the rest as training. Repeat across all folds. Reduces variability vs holdout method.
-
Leave-P-Out – Leave out p observations as the validation set. Repeat across all possible combinations. Becomes expensive for large p.
-
Leave-One-Out – LOOCV leaves one observation out, trains on the rest, and repeats for every observation. No overlap in validation sets but expensive.
-
Repeated Random Subsampling – Split data randomly into training/validation sets multiple times. Average the results.
K-fold cross validation is commonly used as it balances compute time and result accuracy. The most suitable technique depends on your dataset size, model complexity, and other factors.
Cross Validation Process Example
Let’s walk through an example k-fold cross validation workflow:
-
Split data randomly into 5 folds of equal size
-
For each fold:
a) Select fold as validation set
b) Train model on other 4 folds (combined training set)
c) Test model on validation fold and record performance metric (error)
-
Average the performance across all 5 folds
This results in an overall error estimate that should better reflect real-world performance than just training or test error alone. By testing on folds the model hasn’t seen before, we reduce bias and optimism.
You can then use this process when selecting models – choose the one with the lowest cross validation error. It’s also useful for tuning hyperparameters like k in a kNN model. The best k will result in the lowest cross validation error across folds.
Key Takeaways
Cross validation is a crucial technique for better estimating model performance, avoiding overfitting, model selection, and hyperparameter tuning. By testing models on an unseen validation set, it provides a more realistic evaluation of real-world performance. This simple method can lead to substantial gains in predictive accuracy.
Some key points:
- Splits data into training and validation sets
- Tests model on new data for better performance estimate
- Avoids overfitting by revealing any gap with training performance
- Used for model selection and hyperparameter tuning
- Methods like k-fold balance compute time and result stability
( Avoid instability of sampling
Sometimes the splits of training-testing data can be very tricky. The properties of the testing data are not similar to the properties of the training. Although randomness ensures that each sample can have the same chance to be selected in the testing set, the process of a single split can still bring instability when the experiment is repeated with a new division.
Cross-Validation has two main steps: splitting the data into subsets (called folds) and rotating the training and validation among them. The splitting technique commonly has the following properties:
- Each fold has approximately the same size.
- Data can be randomly selected in each fold or stratified.
- All folds are used to train the model except one, which is used for validation. That validation fold should be rotated until all folds have become a validation fold once and only once.
- Each example is recommended to be contained in one and only one fold.
K-fold and CV are two terms that are used interchangeably. K-fold is just describing how many folds you want to split your dataset into. Many libraries use k=10 as a default value representing 90% going to training and 10% going to the validation set. The next figure describes the process of iterating over the picked ten folds of the dataset.
Figure 2: A 10-fold representation of how each fold is used in the cross-validation process.
Figure 2 shows how one fold in each step iteratively is held out for testing while the remaining folds are used to build the model. Each step calculates the prediction error. Upon the completion of the final step, a list of computed error are produced of which we can take the mean.
Figure 3: A graph representation showing training vs. testing size in each value picked for k.
Figure 3 shows the change in the training and validation sets’ size when using different values for k. The training set size increases whenever we increase the number of folds while the validation set decreases. Typically, the smaller the validation set, the likelihood that the randomness rises with a high noise variation. Increasing the training set size will increase such randomness and bring more reliable performance metrics.
One of the advantages of CV is observing the model predictions against all the instances in the dataset. It ensures that the model has been tested on the full data without testing them simultaneously. Variations are expected in each step of the validation; therefore, computing the mean and standard deviation can reduce the information into a few comparing values.
There are other techniques on how to implement cross-validation. Let’s jump into some of those:
( Tuning model hyperparameter
Finding the best combination of model parameters is a common step to tune an algorithm toward learning the dataset’s hidden patterns. But, doing this step on a simple training-testing split is typically not recommended. The model performance is usually very sensitive to such parameters, and adjusting those based on a predefined dataset split should be avoided. It can cause the model to overfit and reduce its ability to generalize.
