As a blogger writing about statistics I often get asked to explain the difference between type I and type II errors. These two types of errors are fundamental concepts in statistical hypothesis testing yet they can be tricky to understand for those without a statistics background. In this article, I’ll explain type I and II errors in simple terms, provide clear examples, and discuss why properly handling these errors is so important in scientific research and data analysis.
What Are Type I and Type II Errors?
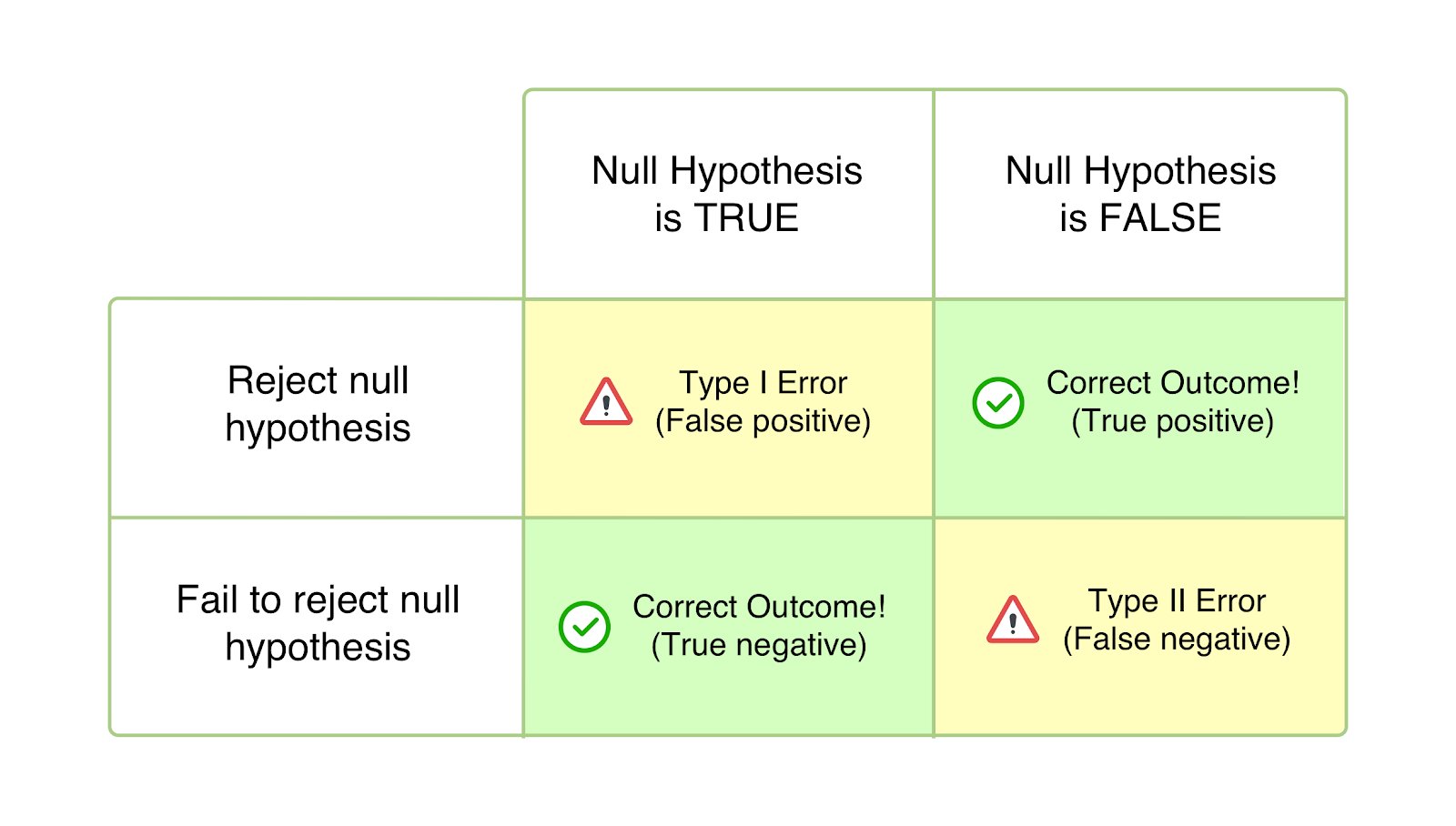
In statistics, we often want to test some claim or “hypothesis” about a population. To do this, we take a random sample from that population and use it to either reject or fail to reject the hypothesis. A type I error means we rejected the hypothesis when we shouldn’t have – it was actually true. A type II error means we failed to reject the hypothesis when we should have – it was actually false.
To understand this, let’s look at a simple example. Say we hypothesize that a new medical treatment is effective. We test this claim by giving the treatment to 50 randomly selected patients and seeing how many improve. If more than 30 patients improve, we will reject the hypothesis and conclude the treatment doesn’t work. If 30 or fewer improve, we will fail to reject the hypothesis and say the treatment is effective.
There are two ways our test could be wrong
-
Type I error: The treatment truly is effective, but by chance, fewer than 30 patients improve in our sample. We incorrectly reject the hypothesis.
-
Type II error: The treatment is ineffective, but by chance, more than 30 patients improve in our sample. We fail to reject the hypothesis when we should have rejected it.
So in plain language:
-
Type I error: False alarm. Concluding something is true when it actually isn’t.
-
Type II error: Missing a discovery. Concluding something is false when it is actually true.
Why These Errors Matter
Mistakes happen in statistics – that’s the nature of using samples rather than populations. But we want to design studies that minimize the chances of each error type. Getting the balance right matters:
-
Too many type I errors waste time and resources on false leads. We might proclaim dozens of new medical treatments as effective when they actually don’t work.
-
Too many type II errors mean we miss out on important discoveries. Truly groundbreaking treatments may be discarded as ineffective due to the study design.
Researchers have to consider the relative harms of each error type for that particular field and topic. In medical testing, a type II error (approving an ineffective treatment) is usually considered worse than a type I error (rejecting an effective treatment). But for law enforcement, a type I error (false conviction) may be viewed as worse than a type II error (letting a criminal go free).
Real World Examples
Let’s look at some real situations where these errors can cause problems:
-
Medical screening: Screens like mammograms aim to detect disease early. But they can spur type I errors, false positives that lead to unnecessary tests and procedures. In the US, up to 15% of mammograms produce false positives.
-
Drug trials: When testing a new medication, misclassifying an ineffective drug as effective (type II error) can expose patients to useless or harmful treatments. But rejecting an effective drug (type I error) deprives patients of potential cures.
-
Justice system: Convicting an innocent person (type I error) is considered a grave miscarriage of justice. But letting a criminal go free (type II error) also has serious consequences for public safety.
Tips for Handling These Errors
So how can researchers design studies to balance type I and II risks appropriately? A few tips:
-
Set a higher significance level (often 0.05 or 0.01) to reduce type I errors. This means we’ll only reject the hypothesis with strong evidence.
-
Increase the sample size to lower the chance of type II errors. Large samples give us more power to detect effects.
-
Use a one-tailed test when an effect in one direction is of interest. This offers more power than a two-tailed test.
-
Select the optimal threshold for diagnostics that classify subjects. Lower thresholds reduce type II errors but raise type I errors.
The Takeaway
Type I and II errors are fundamental concepts in statistics, representing false positives and false negatives in hypothesis testing. Carefully balancing these risks is crucial for sound scientific research and informed decision making. Though eliminating these errors entirely isn’t possible, understanding how to minimize them helps us design rigorous studies and interpret results appropriately. With this knowledge, we can push forward human understanding while avoiding foolish conclusions!
Nursing, Allied Health, and Interprofessional Team Interventions
All physicians, nurses, pharmacists, and other healthcare professionals should strive to understand the concepts of Type I and II errors and power. These individuals should maintain the ability to review and incorporate new literature for evidence-based and safe care. They will also more effectively work in teams with other professionals.
Type I and Type II Errors and Statistical Power Table 1 Contributed by Martin Huecker, MD and Jacob Shreffler, PhD
This book is distributed under the terms of the Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International (CC BY-NC-ND 4.0) ( http://creativecommons.org/licenses/by-nc-nd/4.0/ ), which permits others to distribute the work, provided that the article is not altered or used commercially. You are not required to obtain permission to distribute this article, provided that you credit the author and journal.
- PubReader
- Print View
- Cite this PageShreffler J, Huecker MR. Type I and Type II Errors and Statistical Power. [Updated 2023 Mar 13]. In: StatPearls [Internet]. Treasure Island (FL): StatPearls Publishing; 2024 Jan-.
- PMCPubMed Central citations
- PubMedLinks to PubMed
Type 1 (Alpha) vs. Type 2 (Beta) Error
What is the difference between Type 1, 2?
Type 1 plug is a 5-pin design and has a latch that keeps the plug in place and prevents it from being dislodged from the charger socket, while the Type 2 models, with 7-pin design don’t have these latches. Instead, the vehicles that utilise Type 2 plugs have a locking pin that locates and secures the plug in place.
What is the probability of a type 2 error?
The probability of committing a type I error is equal to the level of significance that was set for the hypothesis test. Therefore, if the level of significance is 0.05, there is a 5% chance a type I error may occur. The probability of committing a type II error is equal to one minus the power of the test, also known as beta.
How to lower both Type 1 and Type 2 errors?
There is a way, however, to minimize both type I and type II errors. All that is needed is simply to abandon significance testing. If one does not impose an artificial and potentially misleading dichotomous interpretation upon the data, one can reduce all type I and type II errors to zero.
What is the definition of type 2 error?
Type II error, commonly referred to as ‘β’ error, is the probability of retaining the factual statement which is inherently incorrect. This is an error of a false positive, i.e., a statement is factually false, and we are positive about it.
