Linear regression is still the most common statistical method used in academia and the data science field to show how features are related. So, Analytics Vidhya made this complete set of interview questions for people who took our Skill Test to see how much they knew about linear regression techniques.
You can take this skill test again if you missed it in real time. Here are the questions and answers so you can check your own work. Note that these are important linear regression interview questions for data analyst and data scientist jobs.
Regression analysis is one of the most important skills for aspiring data scientists to master. As one of the fundamental statistical and machine learning techniques, regression analysis allows data scientists to predict continuous target variables based on the relationship between independent variables.
Whether you are interviewing for an analytics, data science, or machine learning role, you can expect to encounter regression analysis interview questions that test your conceptual knowledge and ability to apply these techniques in practice. In this comprehensive guide, I will share the top 15 regression interview questions with detailed explanations and examples to help you ace your next data science interview
1. What is regression analysis and how does it work?
Regression analysis is a set of statistical methods used for modeling the relationship between a dependent variable and one or more independent variables The goal is to derive a mathematical equation that can describe the behavioral relationship between these variables to predict new observations
Some key points:
- Used for predicting and forecasting of continuous outcomes.
- Relies on correlational relationships between variables.
- Models the data by fitting a best fit line or curve.
- Used across industries like finance, healthcare, retail etc.
At its core, regression relies on minimizing the distance between actual data points and the regression line, known as the ‘least squares method’. The most commonly used regression techniques are linear regression, logistic regression etc.
2. How is regression analysis different from classification?
While regression models continuous target variables, classification models categorical target variables.
In classification, we try to categorize each observation into a class – for example benign or malignant tumor, spam or not spam etc. The output variable is discrete.
In regression, the target variable is continuous, meaning it can have infinite possibilities within a range. Examples are sales projections, house prices etc. The output is numeric.
Classification relies on class boundaries whereas regression relies on finding the best fit using distance metrics. Both have varied applications in machine learning.
3. Explain the difference between linear and logistic regression.
Linear regression is used when the target variable is continuous. It assumes a linear relationship between input and output variables. The predictive model is a linear equation like y = b0 + b1x1 + b2x2 + ..
Logistic regression is used when the target variable is categorical. It assumes a logistic relationship between input and output. The predictive model uses a logistic sigmoid function to predict probabilities like P(Y=1). The function maps linear combinations of features to probabilities between 0 and 1.
While linear regression outputs numeric values, logistic regression outputs the probability of a categorical outcome. Linear regression uses least squares but logistic regression uses techniques like maximum likelihood estimation.
4. What are some common uses cases of regression analysis?
Some common use cases include:
- Predicting house prices based on size, location etc.
- Forecasting future sales numbers and revenues.
- Predicting stock market trends.
- Estimating the risk of diseases based on various health parameters.
- Predicting customer churn and CLV usingRegression techniques are used across industries like real estate, retail, finance, insurance and healthcare for forecasting, prediction and risk analytics.
5. What are the key assumptions made by linear regression?
The key assumptions behind linear regression are:
- Linearity – The relationship between dependent and independent variables is linear.
- Normality – For any fixed value of independent variable, the dependent variable follows a normal distribution.
- No autocorrelation – The error terms should have zero correlation.
- Homoscedasticity – The variance of error terms remains constant across observations.
- No multicollinearity – The independent variables should not be highly correlated.
These assumptions should be validated to ensure a robust regression model. Techniques like residual analysis, Durbin Watson test etc. are used.
6. How do you evaluate regression models? What metrics would you use?
Commonly used evaluation metrics for regression problems are:
- Mean Absolute Error (MAE) – Average of absolute differences between predicted and actual values.
- Mean Squared Error (MSE) – Average of squared differences between predicted and actual values.
- Root Mean Squared Error (RMSE) – Square root of the mean squared error.
- R-squared – Explains the proportion of variance in dependent variable explained by the independent variables. Values range from 0 to 1 where higher is better.
Graphical analysis like residual plots is also used. The choice depends on the business context and need for interpretability vs. precision.
7. How do you handle outliers in regression analysis?
Outliers can significantly skew results of a regression model. Here are some ways to handle them:
-
Plot the data distribution and visually identify outliers. Apply caps or floors to restrict data to cutoffs.
-
Use statistical techniques like Z-scores to remove points beyond a threshold. However, this can lose useful data.
-
Use RANSAC regression – This performs regression using random subsets to estimate inlier vs outlier points.
-
Use robust regression like Theil-Sen instead of least squares. It is less influenced by outliers.
-
Use regularization techniques like ridge or lasso regression. They penalize extreme parameter values.
The approach depends on the data context. It’s important to track model performance with and without outliers.
8. How can you avoid overfitting with regression models?
Some ways to avoid overfitting are:
-
Simplify the model by removing unnecessary variables and polynomial terms based on feature importance.
-
Regularization using L1 and L2 techniques penalizes model complexity leading to simpler models.
-
Ensembling techniques like random forest regression average out multiple deep trees to reduce overfitting.
-
Cross-validation techniques create training-validation folds to test out-of-sample accuracy.
-
Early stopping tracks validation error during training and stops if it starts increasing.
-
Dropout randomly drops a portion of inputs to prevent co-adapting of nodes.
A combination of techniques along with visual analysis provides insights on optimal model complexity.
9. How do you select important variables for regression in a dataset with a large number of features?
Some ways are:
-
Statistical correlation techniques like Pearson coefficient can identify correlated predictors. Highly correlated ones can be removed.
-
Use regularization techniques like Lasso which introduces sparsity and pushes coefficients to zero for unimportant variables.
-
Calculate the univariate regression performance of each variable. Rank and select top features.
-
Use recursive feature elimination to repeatedly train models by removing weakest features until optimal performance is reached.
-
Use tree-based feature importance to understand predictive power of variables in ensemble models.
A combination of statistical as well as algorithm specific techniques provides a robust set of features.
10. You build a multiple linear regression model but find high multicollinearity in the dataset. How would you handle this issue?
Here are a few ways to handle multicollinearity between input variables:
-
Remove highly correlated features – Identify correlation among variables and drop one of the correlated pair.
-
Combine correlated variables into a single predictor – Use techniques like PCA into a smaller set of uncorrelated components.
-
Use regularization methods like ridge regression that penalize and shrink coefficients.
-
Increase the sample size for training data if possible.
-
Use stepwise regression for automated selection of non-collinear variables.
If multiple variables bring in similar information, retaining only significant ones reduces redundancy and overfitting.
11. What are the different types of regression techniques you are familiar with?
Some common regression techniques include:
- Linear regression – Models linear relationships. Simplest case.
- Polynomial regression – Introduces nonlinearity using polynomial terms.
- Ridge and Lasso regression – Uses regularization to prevent overfitting.
- Logistic regression – Predicts categorical variables using logit function.
- Stepwise regression – Achieves subset selection of features.
- ElasticNet – Hybrid of Ridge and Lasso.
- Decision tree regression – Uses decision trees as base learners.
- Random forest regression – Ensemble technique using multiple trees.
Advanced techniques like Support Vector Machines can also be used for regression problems. The technique varies based on problem complexity, computational needs and model interpretability.
12. How does k-Fold cross validation help prevent overfitting in regression models?
K-fold cross validation breaks data into ‘k’ folds and uses each as both training and validation in iterations. For each fold:
- The model is trained on k-1 folds.
- The accuracy is tested on the validation fold.
- This iterates over all folds.
Finally, the performance is averaged across folds. By using unseen data, cross validation provides a more realistic evaluation of model performance than just splitting data once into train-test. It reduces overfitting and variance.
Typical values for ‘k’ range from 5-10 depending on dataset size. Higher k values provide greater validation but increase compute time.
13. What are the advantages and disadvantages of decision tree regression?
Some pros of decision tree regression are:
- Interpretable and easy to explain with visual decision rules.
- Can capture nonlinear relationships like polynomial regression.
- Handles categorical variables and missing values.
- No data normalization required.
Some cons are:
- Prone to overfitting with small datasets. Pruning is required.
- High variance
About the Skill Test
A total of 1,355 people registered for the linear regression skill test. It was made to include many of the most important linear regression interview questions, which cover a wide range of related topics like linear models, coefficients, intercepts, and more. Below is the distribution of the scores of the participants:
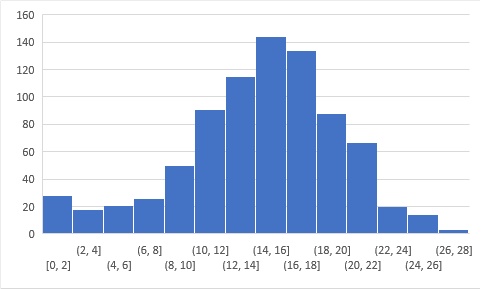 More than 800 people participated in the skill test. The highest score obtained was 28. Here is the leaderboard for the participants who took the test., so you may see where you stand.
More than 800 people participated in the skill test. The highest score obtained was 28. Here is the leaderboard for the participants who took the test., so you may see where you stand.
Here are some resources to get in-depth knowledge of the subject.
If you’re new to Machine Learning and want to learn the basics of AI and Machine Learning, here are some tutorial-based courses that will help you on your way to becoming a data scientist:
Interview Prep Day 2- Linear Regression Interview Question-The Most Important Algorithm In ML & DS
How many regression interview questions are there?
This page lists down 40 regression (linear/univariate, multiple/multilinear/multivariate) interview questions (in form of objective questions) which may prove to be helpful for Data Scientists / Machine Learning enthusiasts.
How many linear regression interview questions should a machine learning engineer know?
Check 25 Linear Regression Interview Questions Every Machine Learning Engineer Must Know and Land Your Next Six-Figure Job Offer! 100% Machine Learning & Data Science Interview Success!
How do you evaluate a linear regression model?
When evaluating a Linear Regression model, it’s vital to use the right metrics to assess its performance. Mean Absolute Error (MAE): Gives the average absolute deviation from the predicted values. It’s easy to interpret but might not effectively penalize large errors.
How do I choose a test for linear regression?
The choice of tests is guided by the underlying data characteristics and the assumptions of linear regression. For instance, if the residuals appear non-normal or heteroscedastic, I might use robust standard errors or transformation techniques.

