Everyone knows garbage in, garbage out when it comes to databases and tables, but even if your data is good at source, you can still hit some bumps in the road when it comes to ensuring the accuracy of the information you and your stakeholders are receiving. That’s where referential integrity comes in.
In database management, referential integrity and data integrity are two crucial concepts for ensuring the accuracy and consistency of data While they sound similar, referential and data integrity focus on distinct aspects of Data Quality.
Understanding the core differences allows data professionals to implement comprehensive safeguards that preserve reliability throughout data systems and processes.
Referential Integrity Overview
Referential integrity deals with maintaining the validity of relationships between database tables and columns containing related data It ensures consistency between interlinked data records, mainly through the use of foreign key constraints
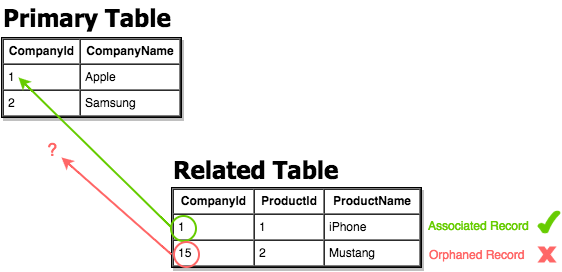
For example, a “customers” table may contain customer ID values that link to order records in an “orders” table. Referential integrity preserves these connections so queries join related data correctly.
Key elements of referential integrity include
-
Foreign Key Constraints – Require a value match the primary key in the parent table. Prevent invalid data.
-
Cascade Operations – Propagate data changes from parent to child tables, like updates to a customer’s info.
-
Restrict Delete – Prevent deleting parent records that have related child records, avoiding orphaned records.
-
Join Integrity – Verify joins between tables reference existing records, preventing dangling references.
Referential integrity is a set of rules and procedures focused on managing table relationships. It prevents database inconsistencies like orphan records, dangling references, and missing relational links.
Data Integrity Defined
Data integrity refers to the overall completeness, accuracy, and validity of data during its lifecycle. It deals with safeguarding data from corruption and unauthorized changes. Data integrity aims to preserve the quality and reliability of information for its intended uses.
Key elements include:
-
Validation Checks – Confirm data meets formatting, type, range, and other requirements.
-
Error Handling – Detect and correct errors in data inputs and transfers.
-
Edit Tracking – Audits to identify who changed data and when.
-
Backups/Recovery – Protect and restore data if corrupted or lost.
-
Access Controls – Allow only authorized users and processes to view and modify data.
-
Encryption – Secure data at rest and in motion to prevent unauthorized access.
Data integrity focuses on the overall trustworthiness and protection of data throughout activities like storage, processing, analysis and reporting.
Key Differences and Relationships
While referential and data integrity share the goal of maintaining reliability, they focus on different layers:
| Referential Integrity | Data Integrity |
|---|---|
| Focuses on table relationships | Focuses on overall quality and validity of data |
| Managed via DBMS rules and features | Managed via policies, procedures, checks |
| Mainly handles structured data | Applies to structured and unstructured data |
| Concerned with database design schema | Concerned with full data lifecycle |
| Subset focused on links and joins | Holistic, covering accuracy, completeness, consistency |
Referential integrity deals with structured data connections. Data integrity covers both structured and unstructured data across the full data lifecycle.
Strong data integrity requires a foundation of proper referential integrity along with comprehensive policies, procedures and controls. Referential integrity is narrower in scope but ensures a key part of reliable data operations.
Examples Demonstrating the Differences
Here are some examples that highlight the distinct focuses:
-
A database architect implements referential integrity by requiring purchase order records include a foreign key linking to existing supplier records. This avoids orders referring to non-existent suppliers.
-
A data analyst checking for data integrity issues uncovers duplicate customer records, inaccurate sales figures, and other anomalies that could undermine reporting. They correct the problems.
-
An ETL developer builds referential integrity checks into the script logic to verify all downstream reference tables are refreshed properly when new parent records are added.
-
A data engineer enables data integrity by hashing data inputs before insertion into the database, then comparing hashes after retrieval to detect tampering.
While sound database design is crucial, comprehensive data integrity also requires policies, change control procedures, validation checks, auditing, security measures, and quality monitoring across the full data lifecycle.
Implementing Both for Reliable Data
Referential and data integrity work synergistically to enable reliable, accurate business information. Some tips for implementation include:
-
Enforce foreign key constraints and cascade operations in the DBMS for referential integrity.
-
Establish data validation checks, error handling, and editing procedures that align with business rules.
-
Enable audit tracking to identify who changed what data and when.
-
Implement access controls and permission levels aligned to job functions.
-
Establish backup, redundancy, and disaster recovery provisions.
-
Mask sensitive data and encrypt where required for protection.
-
Monitor data flows for quality lapses and integrity issues.
Mastering both referential and data integrity concepts allows organizations to enforce reliability while removing barriers to effectively leveraging data for strategic purposes. With robust integrity controls in place, companies can have greater confidence in the information powering data-driven decisions.
Why is referential integrity important?
While normalization is considered critical and, therefore, standard practice — any database would struggle to operate without it — referential integrity is sometimes (incorrectly) considered optional. However, a lack of referential integrity could lead to data inconsistencies, such as incorrect records being deleted, added, or modified. This leads to incomplete data being returned, often without any knowledge of why, when, or even if an error has occurred. Records then become “lost” in the database because they never appear in queries or reports.
The result of this could be far-reaching — for example, on a basic level, it could lead to anomalies appearing in reports that influence business decision-making. Far more critically, it could lead to customers not receiving goods they’ve paid for, or even patients receiving incorrect medication.
Referential integrity vs. database normalization
Referential integrity differs from normalization, although they are interconnected. Normalization is the process of efficiently organizing data in a database, such as eliminating redundant data and ensuring data dependencies make sense. Essentially, it’s the process of specifying and defining tables, keys, columns, and relationships to create an efficient database. Referential integrity, on the other hand, refers to ensuring the quality of the relationships between the tables.
11 03 referential integrity part1
What is referential integrity?
In a database with referential integrity, each time you updated a customer’s information in the contact information table, the database would update the same data in the sales reports table. This eliminates mistakes you can make when entering the same data multiple times in different locations.
What is referential integrity in relational database?
Referential integrity is a property of data stating that all its references are valid. In the context of relational databases, it requires that if a value of one attribute (column) of a relation (table) references a value of another attribute (either in the same or a different relation), then the referenced value must exist.
What is the difference between data integrity and referential integrity?
Referential integrity procedures focus specifically on the relationship between tables and making sure data is consistent. Data integrity rules focus on the entry and retrieval of data. Both are necessary for the correct functioning of the database but happen at different times.
How does referential integrity differ from normalization?
Referential integrity differs from normalization, although they are interconnected. Normalization is the process of efficiently organizing data in a database, such as eliminating redundant data and ensuring data dependencies make sense.
