Before going into causal analysis and inference at any depth, it is important to raise the following questions:
The following aims to answer all those questions by first elaborating on the issues with traditional machine learning approaches.
For making decisions based on real-world data, we often go with a traditional machine learning model. The standard predictive machine learning model can identify the patterns in the data sets and predict accordingly, but the model does not explain the patterns or the reasons for their occurrence. It is not enough just to find statistical patterns in the data; the causal structure in the data also needs to be identified for making appropriate decisions.
The above is the ladder of causation stated in “The Book of Why” by Prof. Judea Pearl, who developed a theory of causal and counterfactual inference based on structural models. Most machine learning and complex deep learning models lie at the bottom-most rung of this ladder because they make predictions only based on associations or correlations amongst different variables. But they don’t give answers to the “what if? and why?” questions which are described in the 2nd and 3rd rung.
Causal inference refers to the process of drawing the conclusion that a specific treatment was the cause of the effect that was observed. The basic principle of causal analysis is to treat the cause rather than the symptoms. A root cause is a fundamental reason why something happens, and it can be quite distant from the original effect.
For building causal models, we mainly use graph structures. However, it is important to understand certain causal terms before understanding a graph structure. Let us see about some essential terms like confounder, treatment, instrument, outcome, and treatment effect.
Confounders: A confounder (also confounding variable, confounding factor, extraneous determinant, or lurking variable) is a variable that influences both the dependent variable and independent variable, causing a spurious association. For example, in the above , smoking can cause both alcohol consumption and lung cancer.
Treatment: The variable having a direct effect on the outcome feature is known as the treatment variable. For example, in the above , alcohol consumption and lung cancer are directly related, i.e., treatment variable is the cause of the effect in the outcome variable.
Instrument: Instrument variable is the one that has direct causal effect on the treatment variable but not on the outcome variable. For example, mental pressure may trigger a person to drink alcohol, but it is not directly related to lung cancer.
Outcome: It is the one that depends or gets influenced by the input feature/independent feature. Simply, it is the one that all the treatment features can manifest. For example, lung cancer is the outcome variable in the above .
Treatment effect: It is the impact created by the treatment variable on the outcome variable. It highlights the difference between potential outcomes when treated vs when not treated. Some of the treatment effect types are listed below.
Here, we explore the methods for implementing causal models in a real-world scenario. Many methods are available for causal model implementation – some of them come up with basic concepts, and some use machine learning concepts. Here is a list of some methods that will help us to build a causal model.
In this method, the parameters having similar values of covariant, i.e., propensity scores, are grouped, and their treatment differences between treated and untreated units are calculated for finding ATE, ATT etc., Propensity score is a single number that summarises all the unit’s covariance. This method is like a standard regression method.
In this method, the entire group is split into homogeneous subgroups. Within each subgroup, the treated group and the control group are similar under certain measurements over covariates, and the treatment effect within each subgroup is calculated. This is mainly used to adjust selection bias.
This method is used when the dataset has too many features for statistical approach, or its effects are not modelled properly. It is recommended to use when the treatment variable is categorical, and all the potential confounders are observed. It helps to estimate heterogeneous treatment effects and uses machine learning algorithms for basic prediction.
This method can also be used when the dataset has too many features. Using a flexible nonlinear approach helps to estimate heterogeneous treatment effects and confidence intervals.
By calculating the response function, the T learner helps estimate the conditional expectations of the outcome separately for control and treatment groups, and their differences gives the heterogeneous treatment effect of the treatment variable on the outcome variable.
The S-Learner is like the T-Learner, except that when we estimate the outcome, we use all predictors without giving treatment variables a special role. The treatment indicator is included as a feature similar to all the other features without the indicator being given any special role.
This method is used when the dataset contains more control groups than treatment groups. It mainly uses information from the control group to estimate treatment effect. This method can also handle overfitting problems.
DML helps to estimate heterogeneous treatment effects and confidence intervals for measuring the uncertainty of the model. This method is recommended when we have a classification type of problem and for the one having a single response. The main advantage of this method is that it aims to correct both regularisation bias and overfitting bias by means of orthogonalization and cross fitting, respectively. DML also comes up with many variants like linearDML, sparseDML, causalforestDML, kernel DML, etc., and it will be used based on the type of dataset.
Use case of the application of a causal model to make decisions in the real-world scenario:
In this case, our main goal is to find the features that mainly influence credit card preference. It will be helpful for the client to do an effective campaign by choosing the right method for a particular customer with minimal cost.
The dataset was obtained from a multinational hospitality company. The obtained dataset contains 297 attributes which includes demographic information, stay details, services details and so on.
For training the model, suitable attributes that contribute more towards the outcome are selected based on domain knowledge. For example, to find the treatment/causal effect of ‘campaign variable’, all the related features need to be fetched from the similar period. Hence for model implementation, only features collected for a one-month duration are considered for training the causal model.
We first build a model based on a traditional machine learning approach by using light gradient boosting. By using Shapley value, the feature having a high impact on the outcome is ordered.
By observing, the traditional model mainly focuses on avoiding lost causes (predicting more accurate negative responses). But as per business perspective, models need to target the sample having a positive response (persuadable customer). Moreover, the traditional model doesn’t show whether the features have a positive impact on the outcome, the percentage of the feature’s influence and how the treatment on different features impacts different segments of the population.
To understand the causal effect, we have moved from the traditional model to a causal model. For implementing the causal model, we choose double machine learning because our target variable is categorical, and we need only one response. The causal model helps to find answers to various causal questions like the following.
Firstly, defining and training the causal model is done with treatment, confounders, and outcome variables. From the causal model, we can get many causal results like,
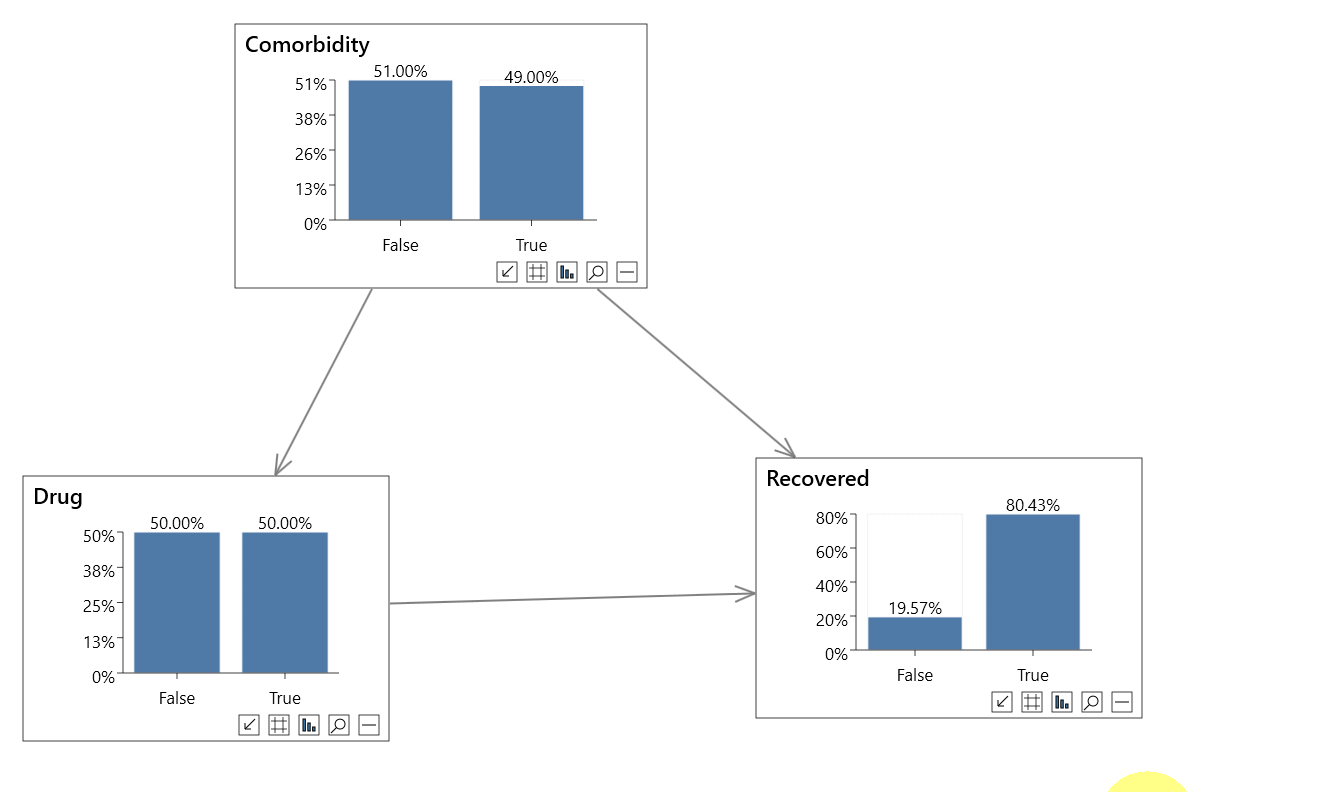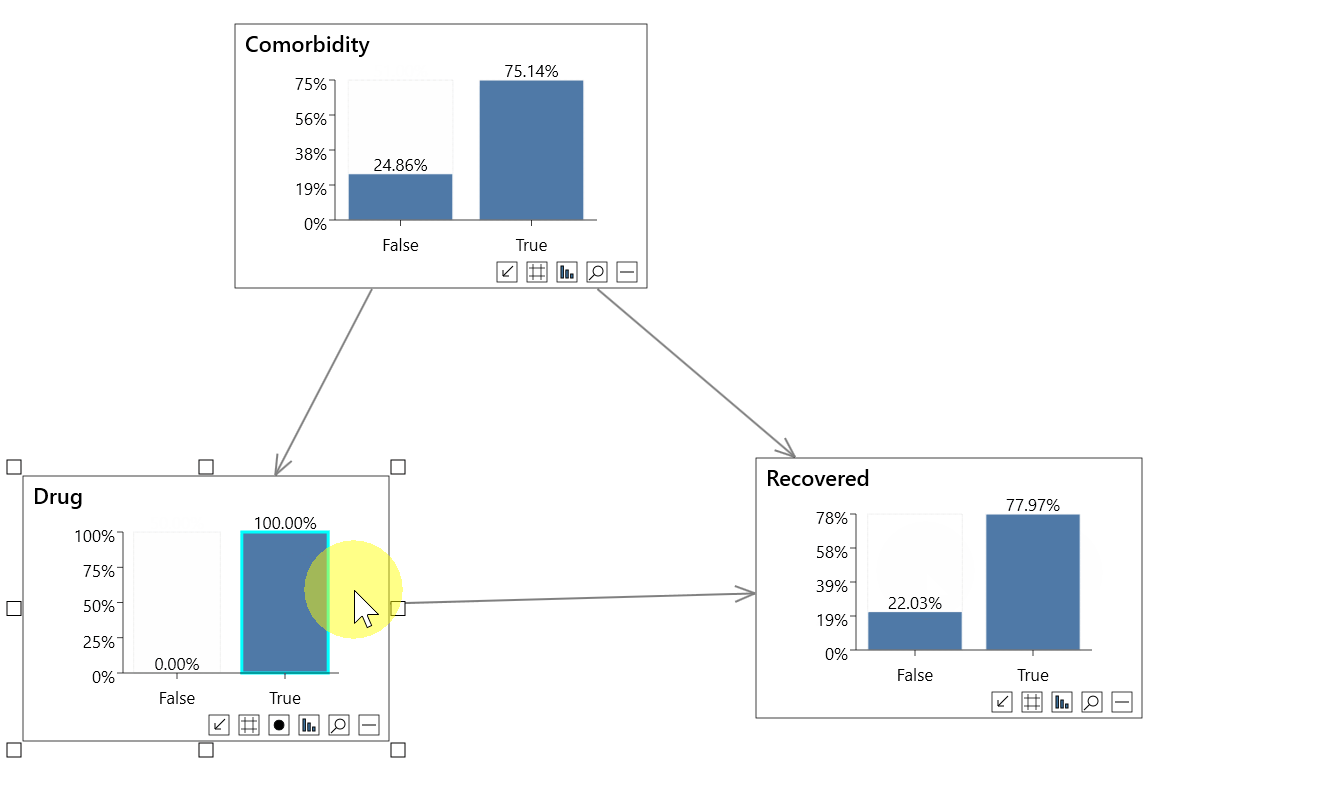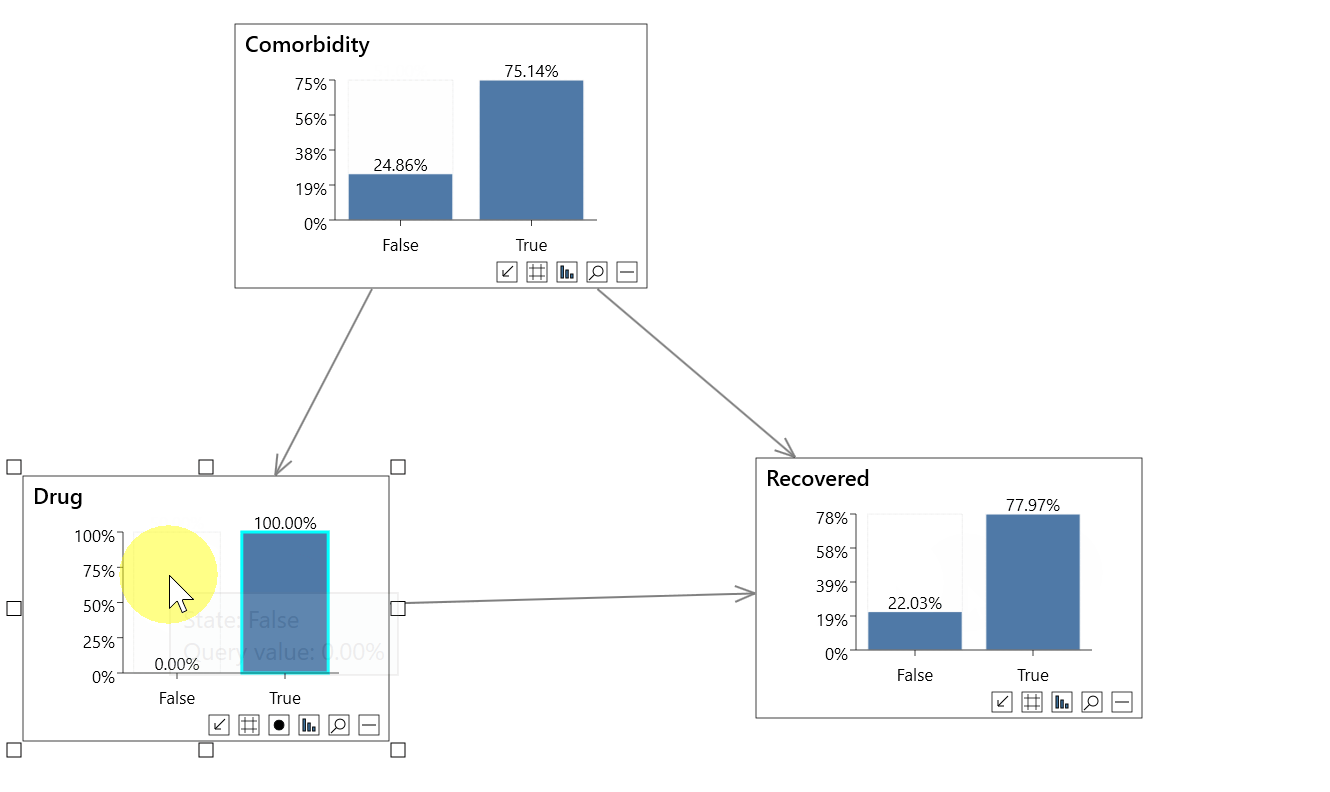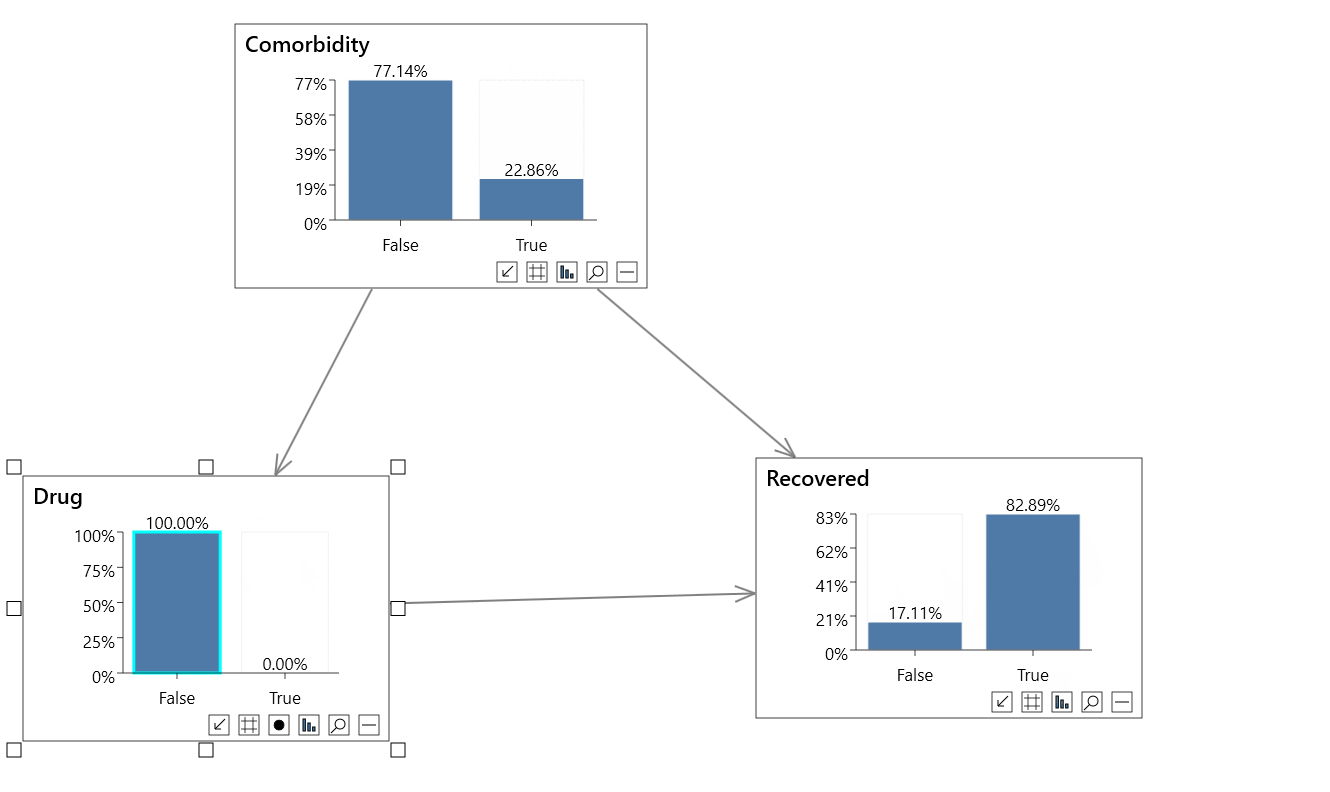
For finding the global treatment effect, the features are sorted based on the p-value, which has above 95% of confidence based on ATE calculated on the entire population for top features.
From the table above, it is clear that attribute 13, attribute 5 and attribute 6 which is basically a treatment variable features have a positive impact on the purchase of credit cards. However, Attributes like 7 (treatment variable), 12, 9 have a negative impact on the outcome. Thus, if more campaigns are done with attribute 7, less would be the choice for credit card purchases.
To predict the customer who is likely to purchase a credit card, customers are sorted based on the most influential causal features. Then we observed that for the top 20% of customers ranked by the causal model, almost 81% of customers showed interest in buying a credit card. It will be useful to target the right customer.
For each customer, corresponding regression coefficient of the treatment variable (marginal cost) obtained from CATE is be taken as a treatment cost, and they are segmented based on their response towards increase or decrease in treatment. For example, segmenting customers based on their response, when they receive an increased number of hotel mails. The impact of the hotel mails on the customer globally and individually is given in the below table.
The result shows that, for any campaign through hotel mails, we can focus only on 1% of customers to get 99% response, instead of 9.6% response on the entire population. This will help the company to target the right customer.
Hence, we can draw the inference that the causal model helps us to obtain multiple causal results, and that these results will be helpful in making accurate decisions under different circumstances. Search
Many enterprises using Databricks for ETL workflows face challenges with isolated data management across workspaces. This…
Businesses are embracing the scalability and flexibility offered by cloud solutions. However, cloud migration often poses…
Streamlit is an open-source Python library designed to effortlessly create interactive web applications for data science…
Causal analysis is a useful problem-solving technique that involves investigating the potential causes behind a specific event or challenge By understanding the root causes, you can develop effective solutions. This guide will walk through the key steps for performing a thorough causal analysis
What is Causal Analysis?
Causal analysis seeks to identify the factors that produced or contributed to a particular outcome It looks beyond superficial symptoms to uncover the underlying causes behind a problem
Some key aspects of causal analysis:
-
It aims to determine cause-and-effect relationships through objective analysis rather than speculation
-
The causes considered may involve methods, materials, policies, human errors, environmental factors, etc.
-
It often utilizes analytical tools like cause-and-effect diagrams, Pareto charts, and root cause analysis.
-
The end goal is to pinpoint the vital few causes to address in order to prevent recurrence of the problem.
Causal analysis draws on principles of scientific inquiry to go beyond guesswork and identify evidence-based causes. It provides vital insights for developing targeted solutions.
Step 1: Define the Key Challenge or Setback
Clearly define the central challenge, setback, or problem you want to investigate with causal analysis. This gives you a specific focus for your analysis.
-
Provide background details on the context. When and where did the issue occur?
-
Describe the challenge in concrete, measurable terms. What are the impacts or symptoms?
-
Determine the scope. Is it an isolated case or pattern?
Establishing a well-defined problem statement upfront ensures your analysis stays focused.
Step 2: Determine the Causes and Effects
Analyze the chain of causes and effects related to the key setback. Look for potential causal factors at each stage that may have contributed.
-
Identify direct causes – failures, errors, or events that immediately resulted in the setback.
-
Determine root causes – fundamental, underlying conditions that allowed the direct causes to occur.
-
Recognize intermediate causes – less obvious factors that influenced root or direct causes.
-
Assess the effects – the specific impacts or consequences of the setback.
Use brainstorming, research, and input from others involved to uncover possible causes. Avoid assumptions.
Step 3: Use a Diagram or Graph
Visually map out the network of causes and effects you identified through a flowchart, fishbone diagram or other tool.
-
Arrows can represent causal relationships and connections.
-
Boxes or circles can hold causes and effects.
-
Categorize causes for easier analysis.
This diagram provides a quick visual reference to analyze the causal factors and their relationships.
Step 4: Formulate a Response to Primary Causes
With your diagram, prioritize addressing the vital few root causes that contributed most significantly to the setback. Develop targeted solutions.
-
For each major root cause, brainstorm prevention strategies.
-
Consider solutions like process improvements, training, equipment changes, policy revisions etc.
-
Identify ways to validate the effectiveness of solutions once implemented.
Addressing a few key root causes often mitigates many other factors down the causal chain.
Step 5: Review and Iterate
Revisit your causal analysis over time to identify any new causes or unintended consequences. Refine your actions to reflect evolving insights.
-
Monitor solution implementation and track metrics related to the original setback.
-
Investigate any deviations from expected results.
-
Add emerging causes and effects to your diagram.
-
Adjust your response plan based on lessons learned from results.
Causal analysis is an iterative process. Reviewing the data helps strengthen your understanding of causes and ability to address them.
Tips for Effective Causal Analysis
Follow these best practices to get optimal value from your causal analysis efforts:
-
Involve team members with diverse perspectives during brainstorming to get a full picture.
-
Use a template or framework to keep the analysis organized and thorough.
-
Document the process through each step to maintain alignment.
-
Challenge assumptions by seeking objective evidence and data to back up causes.
-
Prioritize addressing root causes over superficial factors.
-
Consider both internal processes and external factors when identifying possible causes.
-
Update causal diagrams with learnings so they evolve into useful reference tools.
Examples of Causal Analysis
Causal analysis is widely applicable for investigating problems and guiding solutions. Some examples include:
-
Product defects: Mapping the potential causes from materials, manufacturing processes, employee errors, equipment issues etc. to prevent future defects.
-
Medical misdiagnosis: Analyzing diagnostic process breakdowns, inadequate testing, insufficient information, and other factors leading to incorrect diagnoses.
-
Software failure: Pinpointing root causes like coding errors, insufficient testing, cyber attacks, hardware failures or user mistakes to debug and improve resilience.
-
Workplace injury: Identifying training gaps, protocol breaches, equipment defects, and other causal factors to improve safety.
-
Customer dissatisfaction: Determining failures in quality, service, communications, pricing, or other areas driving complaints in order to regain loyalty.
Causal analysis can reveal the critical roots behind any problem or setback. Uncovering and addressing the vital underlying causes, rather than just the surface symptoms, is key for implementing solutions that truly resolve the issue at hand. With its rigorous, evidence-based approach, causal analysis provides a structured pathway to reveal the origins of a problem and take targeted corrective action.
Services Enabling business leaders to become truly data-driven.
Tailored expertise to transform any sector.
How to Prepare for a Successful Root Cause Analyses + Action Review
FAQ
What are the methods of causal analysis?
|
METHOD
|
PRIORITY LEVEL
|
|
Event and Causal Factor Charting Cause-and-Effect (walk-through) Task Analysis
|
Priority 1
|
|
Change Analysis
|
Priority 2
|
|
Barrier Analysis
|
Priority 2
|
|
Management Oversight and Tree (MORT)
|
Priority 1 (can be used with Events and Causal Factor Analysis)
|
How do you do a causal analysis?
Visual aids can help you connect ideas and organize information better. A causal analysis looks for relationships between causes and effects, so look closely at each cause and identify the relationships between them. You might notice a trend among your key challenges or causes. 4. Formulate a response to the primary causes of your challenge
What is causal analysis in graphical models?
Causal effects from data and graphs Causal analysis in graphical models begins with the realization that all causal effects are identifiable whenever the model is Markovian, that is, the graph is acyclic (i.e., containing no directed cycles) and all the error terms are jointly independent.
What is the central question in the analysis of causal effects?
The central question in the analysis of causal effects is the question of identification: Can the controlled (post-intervention) distribution, P ( Y = y | do ( x )), be estimated from data governed by the pre-intervention distribution, P ( z, x, y )?
What is a causal effect?
The causal effect we have analyzed so far, P ( y | do ( x )), measures the total effect of a variable (or a set of variables) X on a response variable Y. In many cases, this quantity does not adequately represent the target of investigation and attention is focused instead on the direct effect of X on Y.
