The data science hierarchy of needs consists of data collection, moving and storage, exploring and transforming, aggregating and labeling, learning and optimizing, which enables AI and deep learning. Share
For any structure to provide a reliable framework for growth and development, it must begin with a solid foundation. This is true for any type of construct: social, psychological, metaphorical, or physical. While there are lots of visual models that help demonstrate these structural levels, the pyramid—with its strong base supporting its subsequent layers of rising heights—is perhaps the most appealing.
This is the shape chosen to represent Abraham Maslow’s hierarchy of needs, first introduced in his 1943 paper titled “A Theory of Human Motivation”. While Maslow himself didn’t use the pyramid to introduce his idea to the larger study of human developmental psychology, his theory is easily adapted to its shape and structure, and is frequently represented in this fashion.
Maslow’s hierarchy framework rests on the theory that humans have foundational needs which must be met first before they will seek to move to the next level of development. The bottom layers and base of the pyramid contain the deficiency needs, beginning with and building upward from: physiological (food, water, warmth, rest), safety, belonging and love (intimate relationships and friends), and self-actualization/esteem (achieving full potential).
Maslow’s argues that when the first layers of basic needs are not met, people are less likely to be motivated toward transcendence and self-actualization, which occupy the very top of the pyramid. With the basic physiological, safety, and belonging needs settled and satisfied—step by step- it is then possible for a person to work on the higher-level growth needs: cognitive, aesthetic, self-actualization, and transcendence.
The pyramid’s visual shape and the framework of Maslow’s hierarchy both easily lend themselves to the structure of data science and the functionality of its use in business. Monica Rogati uses this model in outlining “The AI Hierarchy of Needs,” substituting Maslow’s human needs with the building blocks of data science. She explains: “Think of AI as the top of a pyramid of needs. Yes, self-actualization (AI) is great, but you first need food, water, and shelter (data literacy, collection, and infrastructure).” If artificial intelligence is at the top of the data science hierarchy of needs, what makes up the foundational layers of the data science pyramid?
Data science has become crucial for organizational success, providing invaluable insights that drive strategic decisions. However, many data science projects fail to deliver business value. A key reason is teams diving into advanced analytics before foundational needs are met.
The Data Science Hierarchy of Needs is a valuable framework for data scientists to prioritize activities and ensure data efforts align to business goals Developed as an adaptation of Maslow’s Hierarchy of Needs, it provides a layered model for staged focus.
Here’s an overview of the Data Science Hierarchy of Needs and how it helps data scientists methodically build capabilities.
Origins of the Data Science Hierarchy of Needs
The Data Science Hierarchy of Needs concept emerged around 2016, likely first formalized by analytics thought leader Vincent Granville. It draws obvious inspiration from psychologist Abraham Maslow’s seminal 1943 paper “A Theory of Human Motivation” which presented his pyramid outlining the progression of basic to growth needs.
Just as Maslow reasoned that humans must satisfy foundational needs before reaching self-actualization, data science projects must nail basics before advancing to sophisticated analytics. The Data Science Hierarchy of Needs translates Maslow’s framework to the data context.
Granville’s early incarnation depicted five layers progressing from collecting quality data up to automation and continuous improvement. Other versions have since emerged, adapting the stages and terminology. But all follow the generalMaslovian premise that data science must evolve in stages with base capabilities established first.
Overview of the Data Science Hierarchy of Needs
While versions vary the Data Science Hierarchy of Needs typically comprises five to seven foundational layers data scientists should tackle sequentially
1. Data Collection
- Gathers raw data from sources like applications, devices, surveys.
- Ensures data quality, accuracy, and completeness.
2. Data Storage
- Stores and manages data in warehouses, lakes, databases.
- Handles large volumes, variety, and velocity of data.
3. Data Processing
- Cleanses, transforms data into analyzable form.
- Connects disparate data sources.
- Structures and formats data.
4. Analytics
- Statistical modeling, visualization, and analysis methods.
- Generates insights from processed data.
- Descriptive, predictive, and prescriptive analytics.
5. Data Products
- Packages analytics into apps, dashboards, reports for business users.
- Operationalizes analytics.
6. Automation
- Automates data science workflows from data collection through model deployment.
- Leverages AutoML, MLOps, scheduling.
7. Continuous Improvement
- Monitors data and models for drift, decay.
- Retrains models.
- Improves data quality and processes.
This presents the core layers though variations modify the specifics. The key is stages follow Maslow’s concept of establishing more basic needs before advancing.
Why the Hierarchy Matters for Data Science Success
The Data Science Hierarchy of Needs helps data teams in several important ways:
Prevents putting the cart before the horse
Data science projects often fail when teams jump right to advanced modeling without solid data, storage, and processing foundations. By laying out prerequisites, the hierarchy prevents this.
Illuminates current gaps
The framework helps data scientists identify which foundational elements are missing or inadequate in the current stack. This shows where investment is needed.
Promotes strategic progress
It provides a roadmap for logical, staged capability building versus haphazard projects. You move sequentially through layers establishing each before advancing.
Allocates resources appropriately
Projects resourced at higher levels won’t succeed if lower elements are not solid. The hierarchy helps allocate budget, people, and time appropriately.
Maximizes project success
Adhering to the staged progress results in more successful deployments, preventing wasted analytics efforts on shaky data.
**Democratizes advanced methods **
Well-established foundations allow expanded access to analytics across the organization versus just data scientists.
The hierarchy gives data teams a structured, needs-based approach rather than ad hoc projects. This results in capability building that reliably unlocks value.
How Data Science Teams Can Apply the Hierarchy
To leverage the Data Science Hierarchy of Needs, data scientists should:
Assess current state
Map existing data capabilities against the hierarchy to identify strengths and gaps in the data stack. Look at people, processes, and technologies.
Prioritize projects
Use the hierarchy as a lens for evaluating and sequencing proposed projects. Ensure you build on strength rather than skipping ahead without solid footing.
Establish roadmaps
Create data science roadmaps incorporating staged advancement across layers of the hierarchy versus disjointed initiatives.
Secure investment
Educate executives on foundational investments needed using the hierarchy framework to demonstrate prudent stewardship towards value.
Evaluate new solutions
Vet data tools and technologies against your current spot on the hierarchy. Will they appropriately progress capabilities versus over-engineering?
Promote democratization
Use the model to show how establishing strong data foundations ultimately allows wider analytics adoption beyond just specialized data teams.
Key Takeaways
The Data Science Hierarchy of Needs evolved as a way to apply Maslow’s foundational concept to the data science context. It provides a logical, staged model for building capabilities that prevents common pitfalls of overengineering on shaky data.
While versions differ slightly, the frameworks generally present layers progressing from collecting quality data up to continuous improvement of automated systems. Data teams that thoughtfully follow the hierarchy avoid putting the cart before the horse and see greater analytics success.
By illuminating current gaps and promoting strategic capability building, the Data Science Hierarchy of Needs is a valuable tool for data scientists. It helps teams methodically construct the foundations empowering game-changing analytics. The hierarchy ultimately lets you climb to self-actualization, in Maslow parlance, or decisive data-driven advantage in business terms.
Examples Walking Through the Data Science Hierarchy of Needs
To better understand application, let’s walk through some examples taking a phased, hierarchy approach:
Big Box Retailer
A large retailer wants to improve inventory management by predicting demand signals for better restocking. Their data science hierarchy evolution could be:
Data Collection: Implement scans to collect point-of-sale and inventory data.
Data Storage: Build a data lake architecture on cloud infrastructure.
Data Processing: Streamline ingestion and implement methods for handling anomalies, missing data, and transformations for analysis.
Analytics: Statistical forecasting models to find signals correlating to stock outs.
Data Products: Yield/availability dashboard for supply chain.
Automation: Refresh prediction models weekly based on latest sales data.
Continuous Improvement: Monitor model accuracy and retrain as needed.
Healthcare System
A hospital network wants to leverage data science for improved patient outcomes. Their hierarchy journey may involve:
Data Collection: Integrate disparate systems like medical records, billing, pharmacy, and more.
Data Storage: Create a scalable data warehouse and governance rules.
Data Processing: Standardize terminology and map patient journeys.
Analytics: Risk models flagging patients prone to readmission.
Data Products: Alert system for care managers.
Automation: Auto-score all patients with risk algorithm nightly.
Continuous Improvement: Monitor model performance, re-develop as needed.
Online Retailer
An ecommerce firm wants to optimize online marketing spend. Their hierarchy approach could entail:
Data Collection: Import campaign expenses, website analytics, and sales data.
Data Storage: Build cloud data lake with defined schema.
Data Processing: Connect data sources, cleanse records, engineer features like ROAS.
Analytics: Marketing mix models reveal campaign efficiencies and impact.
Data Products: Marketing dashboard highlighting spend optimization opportunities.
Automation: Schedule reports and refresh models weekly.
Continuous Improvement: Add new data, refine models periodically.
These examples demonstrate applying the hierarchy thinking to focus valuable data science efforts for business results.
Key Takeaways on the Data Science Hierarchy of Needs
- The hierarchy provides a logical roadmap for sequenced data capability building.
- It helps prevent common problems like overengineering analytics before fundamentals are established.
- Mapping your organization against the hierarchy illuminates gaps to address.
- Following the layers methodically results in impactful data science investments.
- The hierarchy ultimately enables democratizing analytics across the business.
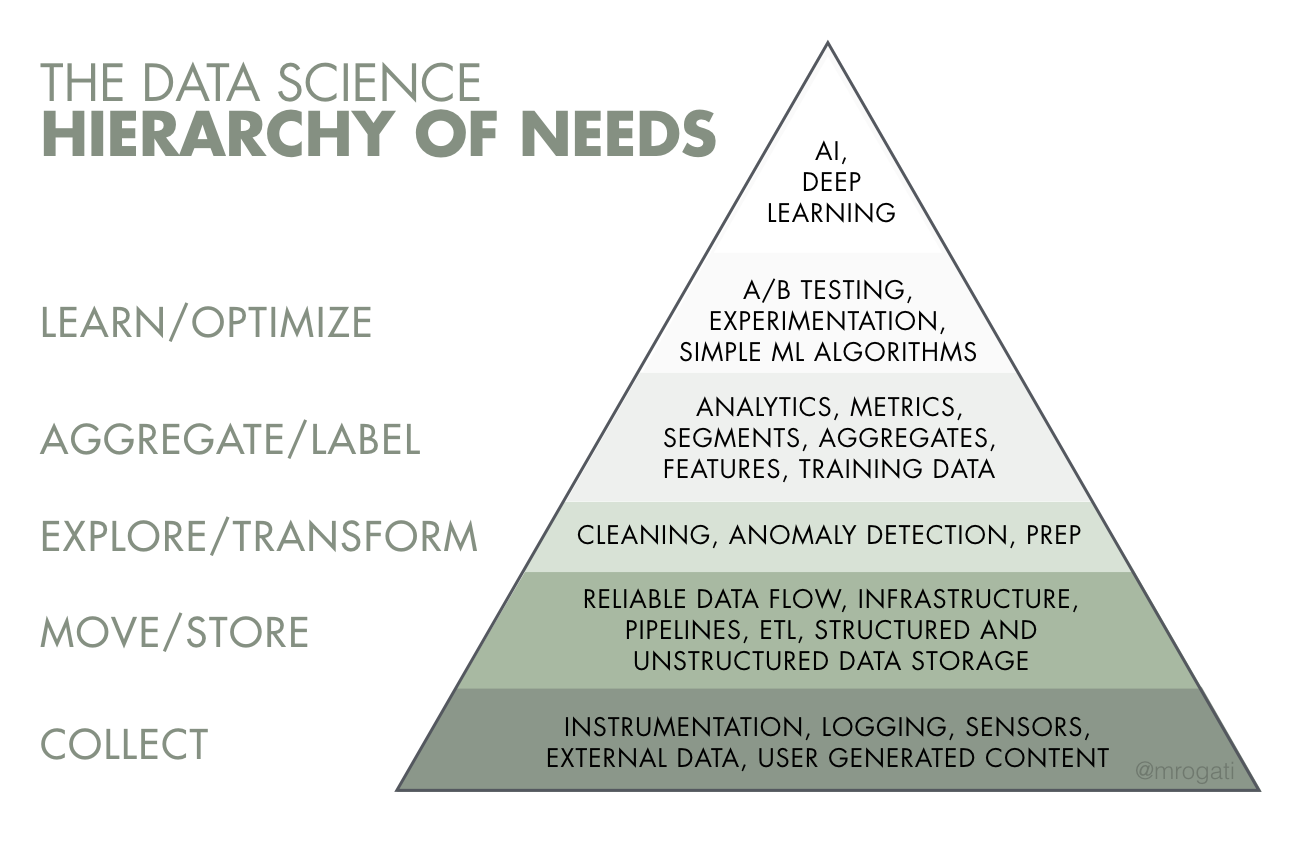
What is the hierarchy of needs in data science?
Rogati argues that companies must prepare for data collection and require a reliable and effective framework in place to benefit from the information the company collects. It’s just not possible to begin by building machine learning algorithms without data structure in place. “More often than not, companies are not ready for AI. Maybe they hired their first data scientist to less-than-stellar outcomes, or maybe data literacy is not central to their culture. But the most common scenario is that they have not yet built the infrastructure to implement (and reap the benefits of) the most basic data science algorithms and operations, much less machine learning.”
To follow Maslow’s model and work from the foundation up, we need to start with data collection: What data do you need, and what is available to you? This is a critical stage for any data-driven enterprise. It provides the footing for the loftier goals of the company.
According to data science consultant Matthew Renze, “The most basic need of a data-driven organization is the need to collect data. This starts with basic data collection activities like recording transactions, logging errors, and digitizing analog data.” Before moving to the next pyramid level, organizations need to look at the data coming through sensors and the ways relevant user interactions are being logged to create a solid dataset.
With accurate, reliable, and complete data collection, an organization is ready to advance to securing movement, organization, and storage—or monitoring how the data flows through the system. Accessible data is useful data, and this is the stage to test data sources and sensors. Basic, unstructured organization begins here, with further structure and storage development to follow.
The next level of the data science hierarchy of needs pyramid involves exploration and data analysis through anomaly detection and data cleaning. This is an important step in preparation for a more robust organization of data at the next level. If the results are less than stellar, it may be time to check the first-level foundation and refocus on collection methods.
Once data is reliably explored and organized, metrics can be defined and analytics can begin. Data storage becomes more important as the company matures, which may lead to more robust solutions.
As we near the uppermost level, the pyramid has achieved analytics, metrics, and training data. Now it’s time to test, learn, and optimize data usage. Are you ready for machine learning? According to Monica Rogati: “Maybe, if you’re trying to internally predict churn; no, if the result is going to be customer-facing. We need to have a (however primitive) A/B testing or experimentation framework in place, so we can deploy incrementally to avoid disasters and get a rough estimate of the effects of the changes before they affect everybody.”
Online Master of Science in Computer Science Software Engineering Concentration (no CS background required)
MS in Computer Science at University of Tennessee-Knoxville
You can earn your degree entirely online in as few as 24 months while working full-time.
Data Science Team Structure & Data Science Hierarchy of Needs
What is a data science hierarchy of needs?
The data science hierarchy of needs is a model that demonstrates the foundational principles necessary for more advanced computer processes like machine learning and artificial intelligence. The model is in the shape of a pyramid, with the bottom levels featuring simpler tasks like data collection and storage.
What is a data science hierarchy of demands?
A model that highlights the underlying principles necessary for more complex computer operations such as machine learning and artificial intelligence is called the data science hierarchy of demands. The paradigm takes the form of a pyramid, and the lower levels consist of more straightforward responsibilities, such as data gathering and storage.
What is the ‘hierarchy of needs for data-driven companies’?
Data teams are tasked with building a data stack to support business needs in what we classify to be the “Hierarchy of Needs for Data-Driven Companies.” The hierarchy looks like this: Business-critical data is sitting in dozens, if not hundreds, of different sources.
What is the analytics hierarchy of needs?
The general idea of the analytics hierarchy of needs is that you should not move up the hierarchy until you’ve done the basics in the prior step (i.e. no deep analysis before metrics are defined & tracked, no dashboards built before you’ve started collecting & cleaning your data, etc). The Analytics Hierarchy of Needs. Image by Author 1. Collect
